The mathematics behind monitoring
… inspired by Prometheus metrics
First and foremost I highly recommend reading this article which provides an introduction to monitoring and observability and why we need them.
Monitoring includes many types of concepts logging, tracing, and event introspection. At the most basic level monitoring allows us to gain visibility into a system, in order to check its health and diagnose it when things go wrong.
A good entry point in this journey is a quote from Google’s SRE workbook.
“The metrics you retain about events or resource consumption should ideally be monotonically incrementing counters.” — Site Reliability Workbook by Google.
Let’s break it down…a monotonic function represents a function that increases or decreases in its entire domain, and a counter basically counts things.
The latter actually boils down to a cumulative metric whose value can only increase or be reset to zero on restart, which is a COUNTER (e.g. total no. of HTTP requests, CPU seconds spent).

What happens when we have a scalar that can arbitrarily vary, meaning that it is a counter that can go up or down? We use a GAUGE for things like the number of running processes, memory usage, or the number of items in a queue.
Usually, when we want to track change over time, we use something named TIME SERIES which is a series of data points indexed in time order at a regular time interval.

And in order to represent a distribution of numerical data, we can use HISTOGRAMS. The histogram groups the data into buckets/bins and counts how many values are in each bucket/bin.
So when there’s a need to measure some observations (size of events usually — how long they take) we can count those observations in buckets using HISTOGRAMS, e.g. latency /request durations, function runtimes, or response sizes. If we use cumulative buckets then we have a cumulative HISTOGRAM.


Let’s take a concrete example in which we want to calculate the average duration of an HTTP request over the past 5 minutes.
We need to do a cumulative count of all observations for the requests and a cumulative sum of the values of our observations for the requests, and last but not least we need a function that shows at what rate the counter increased per second over a defined time window (5 minutes in this case).
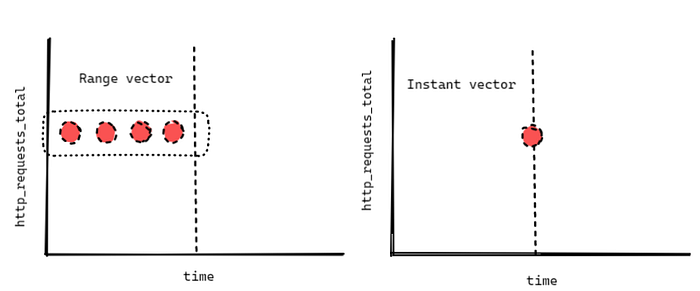
rate(prometheus_rule_evaluation_duration_seconds_sum[5m]/rate(prometheus_rule_evaluation_duration_seconds_count[5m])The rate function is of high importance because it can calculate per second (usually) the average rate of increase of the time series in the set of time series samples (range vector). Meaning more exactly that something like http_requests_total is an instant vector, while http_requests_total[5m] is a range vector .
Sometimes we may need quantiles (e.g. summaries), where a quantile represents a cut point, or line of division, that splits a distribution into continuous intervals with equal probabilities.



φ-quantiles are quantiles that cut a set into “φ” subsets of nearly equal sizes. There are various names for the specialized forms of quantiles. For example, a 2-quantile, or a quantile with 2 partitions, is known as the median.
In conclusion, I will leave some of the best practices recommended by Prometheus documentation:
- If you need to aggregate, choose histograms.
- Otherwise, choose a histogram if you have an idea of the range and distribution of values that will be observed. Choose a summary if you need an accurate quantile, no matter what the range and distribution of the values are.
Since this discussion was mainly focused on Prometheus metrics, I will share some nice tips and tricks with regard to Grafana and Prometheus monitoring.
